Abstract
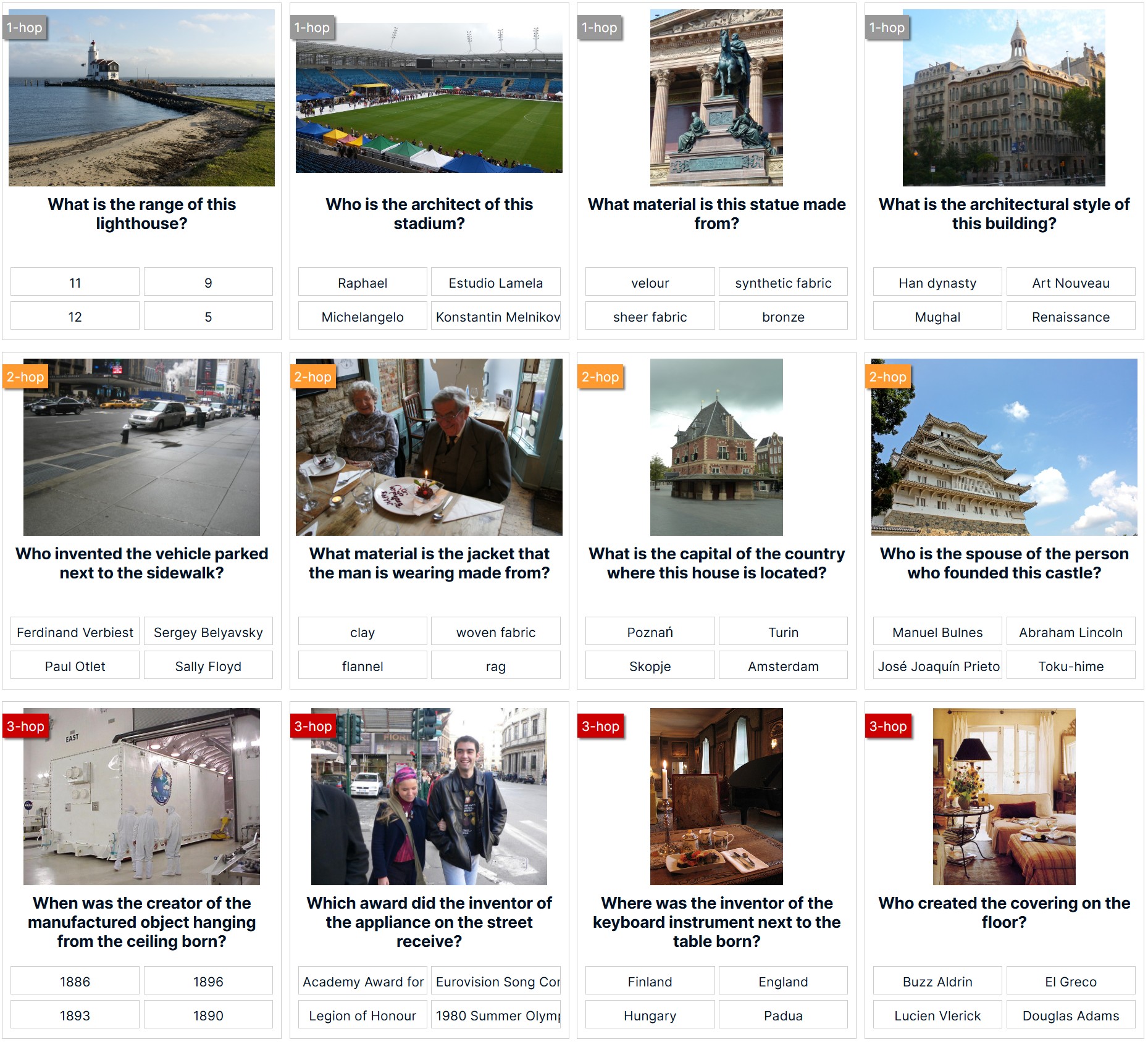
In this paper, we propose a new dataset, ReasonVQA, for the Visual Question Answering (VQA) task. Our dataset is automatically integrated with structured encyclopedic knowledge and constructed using a low-cost framework, which is capable of generating complex, multi-hop questions. We evaluated state-of-the-art VQA models on ReasonVQA, and the empirical results demonstrate that ReasonVQA poses significant challenges to these models, highlighting its potential for benchmarking and advancing the field of VQA. Additionally, our dataset can be easily scaled with respect to input images; the current version surpasses the largest existing datasets requiring external knowledge by more than an order of magnitude.
BibTeX
@InProceedings{Tran_2025_ICCV,
author = {Tran, Duong T. and Tran, Trung-Kien and Hauswirth, Manfred and Le Phuoc, Danh},
title = {ReasonVQA: A Multi-hop Reasoning Benchmark with Structural Knowledge for Visual Question Answering},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {18793-18803}
}Acknowledgement
This work was partially funded by the European Union's programme under grant agreement No.101092908 (SMARTEDGE), by the Chips Joint Undertaking (JU), European Union (EU) HORIZON-JU-IA, under grant agreement No. 101140087 (SMARTY) and by the German Research Foundation (DFG) under the COSMO project (ref. 453130567).